Interior Gateway Protocols (IGPs)
IGPs are used for routing within an autonomous system (AS) or an internal network. They help routers exchange routing information and make routing decisions within the boundaries of the AS. Some common IGPs include Routing Information Protocol (RIP), Open Shortest Path First (OSPF), and Intermediate System to Intermediate System (IS-IS). IGPs are typically used to facilitate communication and routing between routers within a single organization or network.
Key characteristics of IGPs:
- Used for routing within a single autonomous system or internal network.
- Exchange routing information between routers within the same network domain.
- Typically focus on factors such as shortest path or link cost when making routing decisions.
- Examples include RIP, OSPF, IS-IS.
Exterior Gateway Protocols (EGPs):
EGPs, on the other hand, are used for routing between autonomous systems (ASes) or different networks operated by separate organizations. Their primary purpose is to exchange routing information between different ASes on the internet. The most widely used EGP is the Border Gateway Protocol (BGP), which enables routers to exchange routing information across multiple networks and make routing decisions that span across AS boundaries.
Key characteristics of EGPs:
- Used for routing between autonomous systems or different networks.
- Exchange routing information between routers in different ASes.
- Focus on factors such as AS path, policies, and external reachability when making routing decisions.
- Examples include Border Gateway Protocol (BGP).
In summary, IGPs are employed for internal routing within a network or autonomous system, while EGPs are used for routing between autonomous systems or different networks. The scope, routing decision factors, and the protocols used are the primary distinctions between these two types of gateway protocols.
]]>When the “no auto-summary” command is configured under the EIGRP routing process, it prevents automatic summarization from occurring. This allows more specific (subnet-level) routes to be advertised and exchanged between routers, providing greater flexibility in routing and preserving the full network topology.
Disabling auto-summary is often recommended in scenarios where Variable Length Subnet Masking (VLSM) is used, as it allows for more efficient utilization of IP address space and enables the routing protocol to advertise subnets more accurately.
By using the “no auto-summary” command in EIGRP, you ensure that routes are propagated with their original subnet masks, enabling more precise routing decisions and finer control over network traffic flows.
]]>Yeah!
The topic I like to discuss today is about port-channel in Nexus. Port-channel bundles physical links to form one logical link by using the channel group that provides aggregated bandwidth and redundancy. On the M-series module, you can bundle up 8 physical links but with the release of Cisco NX-OS 5.1, you can bundle up to 16 ports on the F series module. The Port-channel feature does not need a license in order for you to use it. However, since you are going to use VDCs, you need to have the Advanced Services license. This need to be installed before you configure ports within the VDC. Make sure that all member ports are in the same VDC. You can have them configured in any desired VDC but if you are going to configure the load balancing, you must do it in the default VDC.
Though they always said that it’s not good to compare, it’s not true in the networking technology or maybe in other technologies not only in the network world. We always compare. Like in IOS, NX-OS requires all the members of port-channel to have compatible parameters. Else, the port-channel will not form.
So, the first thing that you need to do is to verify whether the following parameters are the same for all member ports:
- port mode
- speed
- MTU
- shut lan
- MEDIUM
- span mode
- load interval
- Access VLAN, Trunk native VLAN, and Allowed VLAN list
- 802.3x flow control setting
How do you do that? Use the “show port-channel compatibility-parameters” command. We will discuss more of it in my future port-channel lab post.
Another thing that is important to take note is that Cisco NX-OS does not support PAgP. The Cisco proprietary Port Aggregation Protocol (PAgP) is not supported for some reasons.
PORT-CHANNEL TOPICS:
- Default Port-Channel Parameters
- Port-Channel Basic Settings
- Configuring Port-Channel
- Port-Channel Load Balancing
- Port Channel Verification
Remember the split horizon rule in iBGP? Route Reflector (RFC 4456) is one of the three solutions and often use as an alternative to Full Mesh topology. Route Reflectors allows iBGP speaker to have partial mesh topology while still propagating iBGP routes to another iBGP speaker. It modifies the iBGP split horizon rule by allowing the router to forward incoming iBGP updates to an outgoing iBGP session under. With Route Reflector, it lowers CPU and memory requirements by reducing the number of TCP sessions to be maintained.
Route Reflector has two iBGP peers: Client peers and Non-Client peers. Route-Reflector clients behave like normal iBGP routers. They are not required to form full mesh, can have any number of eBGP sessions and they can have only one iBGP session and that is the connection to Route-Reflector. When Route Reflector fails, they can no longer receive or send updates to the rest of the AS. In this kind of design, Route Reflector represents a single point of failure. In order to solve this, we need redundant Route Reflectors. Each Clients needs to connect to redundant Route Reflectors. Route Reflectors receive the same iBGP update from its Clients and reflect it all other Clients and Route Reflectors send same routes to each Clients.
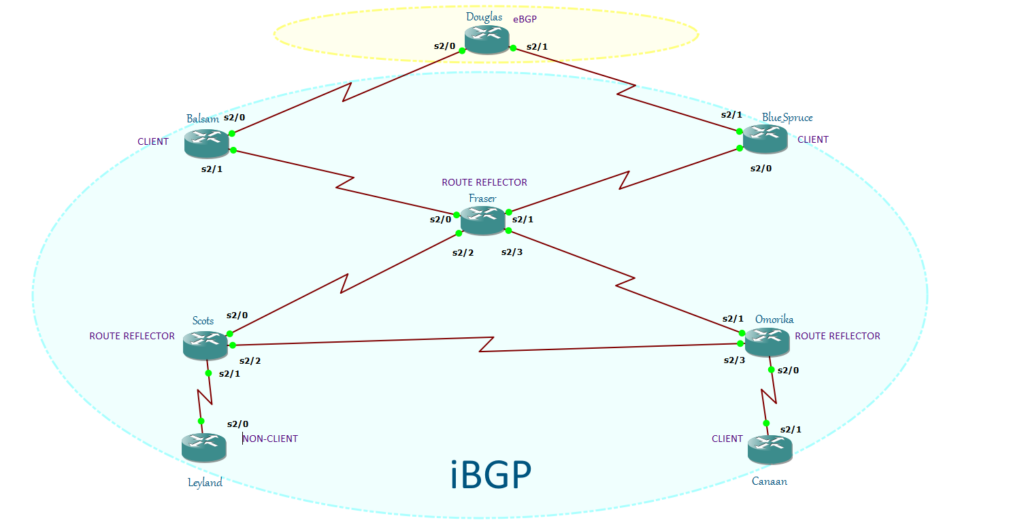
The use of redundancy in Route Reflectors may introduce routing loops in the network. However, no need to worry as Route Reflector has Cluster_List and Originator_ID attributes.
Route Reflector and its Clients formed a cluster. Each cluster must have a unique Cluster ID. The Cluster ID is being prepended to the “Cluster_List” each time the route is being reflected. Cluster_List is an Optional Non-Transitive BGP attribute. Remember the BGP Path selection process? It is the 12th criteria of BGP selection attribute. Like AS Path, the minimum cluster list length is more preferred. Also like AS Path, it shows the path the route has passed. It also serves as a loop avoidance mechanism as it discarded routes with the same local Cluster ID. Take note that Cluster ID is configured in Route Reflector. When a Route Reflector receives a routing update from another Route Reflector in the same cluster, it rejects the update.
There is another loop avoidance mechanism of Route Reflector and that is the Originator_ID. It is another Optional Non-Transitive BGP Attribute and as the name suggests, it identifies the originator of the route. The router ID is added as the Originator_ID to the route when received from eBGP peer and when there is already one exists, a router needs not to add another Originator_ID. When a routing update is received from the same local Originator_ID, then the update is discarded.
All other that are not part of the cluster are non-clients. Non Clients do not support Route Reflector functionalities. Unlike with Clients, Non-Clients need to fully mesh.
Route Reflector Forwarding of Prefixes Rules
Route Reflector propagates eBGP learnt prefixes and iBGP prefixes learnt prefixes from Clients and Non-Clients to Clients. Route reflector propagates eBGP learnt prefixes and iBGP learnt prefixes from Clients to Non-Clients. It will not forward learnt iBGP prefixes from Non-Clients to Non-Clients.
Before we end this discussion, there is one more important thing to remember. A Route Reflector can reflect route only within a single cluster. It can participate in multiple clusters but only as a client. A client can only function as a client only to Route Reflector belonging to the same cluster.
]]>| Version | Opcode | Checksum |
| Flags | ||
| Sequence | ||
| Acknowledgement | ||
| Virtual Router ID | Austonomous System (AS) | |
Believe me or not, aside from passing an exam there is another important reason why you should know what is inside the EIGRP packet header. Any hypothesis?
The Job Interview
You thought you know everything when you got the Cisco professional level certification but what happens when the interviewer asked you about what is inside the EIGRP packet header? You memorized all the configurations commands. You know what is BGP route reflector. You know how to do unequal load balancing in EIGRP. You even know how to configure fabric path, ASA firewalls, and do site-to-site VPN. You know everything you did in your laboratory but you forgot what is inside the EIGRP packet header.
“Who is going to ask me this stupid question?”
I guess an interviewer who has a doubt about your skills most especially if you put all your certifications on your resume. Funny, but it is pretty quite true.
“Is the interviewer going to judge me if I forgot what EIGRP packet header contains?”
Uhm, maybe. Depends on many reasons. We can say, the interviewer is using a bottom-up approach. In this way, it saves time and may not continue asking you further questions if you did not know the basic. Or, it can be a warm-up for more heart-pounding questions.
“What if you just forgot and neglect it during the academy session?”
I don’t think the interviewer will be interested in that kind of reason. So, if you were not able to answer, you better pray that the interview will not stop there.
I don’t want to scare you because this is just a legend. It is a traditional story popularly regarded as historical but nobody wants to confirm the truth. Anyhow, it is just my way to open up our “EIGRP Packet Header” discussion.
- Version – This is the EIGRP header version with the current version of 2. This is a 4-bit field and it is not the same as the TLV version field.
- Opcode – Remember the EIGRP packet types? This is how EIGRP neighbors know what kind of packet type it is. It is a 4-bit field as well like the version field and below is the equivalent values of message types:
EIGRP Message TypeOpcode ValueUpdate1Request2Query3Reply4Hello5Reserved6-9SIA Query10SIA Reply11 - Checksum – this is 24-bit field standard IP checksum. If the packet fails the checksum, the it is discarded.
- Flags – This is a 32-field that defines special handling of the packet. There are 4 flag bits: INIT flag (0x01), Conditionally Received (CR) flag (0x02), Restart (RS) flag (0x04), and End-of-Table (EOT) flag (0x08). For newly discovered neighbors, the bit is set in the initial UPDATE. The INIT flag instructs the neighbor to advertise its full set of routes. CR flag is that receivers should only accept the packet if they are in Conditionally Received mode. RS flag is set in the HELLO and UPDATE packet. It is an indication that the neighbor is doing a soft restart. This In this way, adjacency is maintained. When EOT flag is set, it indicates that the neighbor has completed sending all updates. This indicates the neighbor can flush all stale routes prior to restart event.
- Sequence – Every packet sent to the neighbor will have a 32-bit sequence number that is unique to the sender. When the value is set to 0 that means it doesn’t require any acknowledgement.
- Acknowledgement – this is another 32-bit field sequence number that is unique to the receiver.
- Virtual Router ID – This is a 16-bit number that distinguishes the virtual router a packet is associated with. Any value other than listed below, will be discarded:
- Autonomous System – This is the most important part in the EIGRP packet header. This is a 16-bit number which value ranges from 1 – 65535. AS should match on all EIGRP neighbors or else packet will be ignored and there will be no adjacency.
OSPF IN DOWN STATE
Hello packets are very important parameters in establishing adjacency in any routing protocol not only in OSPF. Now, if no hello packets have been received from the neighbor and the dead timer interval has expired, OSPF is in DOWN state. The first OSPF neighbor state is “DOWN” state. It usually happens on Non-Broadcast MultiAccess (NBMA) networks and Non-Broadcast Point-to-Multipoint networks where neighbor is manually configured.
OSPF IN ATTEMPT STATE
“ATTEMPT” state only exist on NBMA networks. The router is sending Hello packets but these are not received by its peer.
OSPF IN INIT STATE
This is the same with the “CONNECT” state of BGP. When OSPF is in INIT state, that means that the router sees the Hello packets from the neighbor but the two way communication is not yet established. The receiving router should list its own router ID to acknowledge that it has a received a valid Hello packet.
It is not good to see a neighbor that stays on “INIT” state for a long time. There are many reasons why OSPF neighbor adjacency is stuck in “INIT” state.
- It can be a configuration/mismatch on the following parameters like Hello/Dead Timers, network mask, and Area ID.
- It can be an authentication issue. When authentication is used, make sure that authentication type and authentication key matches on both ends.
- For some reason, an access-list for OSPF multicast address 224.0.0.5 is being denied, this also causes the router to stay in “INIT” state. This address plays an important role in the two-way communication because this is the destination address of Hello packets.
- If you are configuring static frame-relay and/or dialer map and you forgot the “broadcast” keyword, it would also be an issue and make you stuck in this state. The use of the “broadcast” keyword is required if broadcast and multicast traffic is to be sent over the specified DLCI.
- Finally, it can be a Cisco bug (Cisco bug ID CSCdj01682). Try to issue “show ip ospf interface” command and check the “Neighbor Count” and “Adjacent Neighbor Count.” If the “Adjacent Neighbor Count” is higher than the “Neighbor Count” then it could be a bug.
OSPF IN 2WAY STATE
At this stage, two-way communication has been established. The router has seen its own router ID in the neighbor field of the neighbor’s packet. Do not be alarm if your routers are in “2WAY” state. In a multiaccess segments where DR and BDR are present, all DROTHERS (Not DR/Not BDR) will stay in “2WAY” state. This is normal and expected behavior as those routers will synchronize their database with DR and/or BDR only.
When there is no issue, the router checks if it is already listed as neighbor in its peer. If it is, it resets the dead timer and neighbor relationship is already formed. If not, it goes to “EXSTART/EXCHANGE” state.
OSPF IN EXSTART STATE
This is the state when the bidirectional communication has been established and in multiaccess segments, where DR and BDR election is completed, the routers enter the “EXSTART” state and start the Master/Slave relationship. In a Master/Slave relationship, it is determined by highest priority and/or router ID.
OSPF IN EXCHANGE STATE
Once the Master/Slave relationship is negotiated, the Master starts the exchange of Database Descriptor. After Master sends its DBD, the Slave sends its own DBD. If no issue occurs, it goes to “LOADING” state. However, if OSPF is stuck in “EXSTART/EXCHANGE” state the main reason is a mismatched MTU. It usually occurs when connecting a Cisco router to non-Cisco router.
A router with the higher MTU continues to accept the DBD packet of the router with the lower MTU. It will be stuck in “EXCHANGE” state. On the other hand, the router with the lower MTU will stay in “EXSTART” state. It will discard the DBD packets and will continue to retransmit the initial DBD
OSPF IN LOADING STATE
Once DBDs are acknowledged and reviewed, it now goes to “LOADING” state. OSPF stuck in “LOADING” state and generates OSPF-4-BADLSA error message is not normal. This means that LSA being exchanged is corrupted. Contact Cisco TAC support.
OSPF IN FULL STATE
IN “FULL” state, neighbors have formed and they have now the same Link State Database (LSDB).
]]>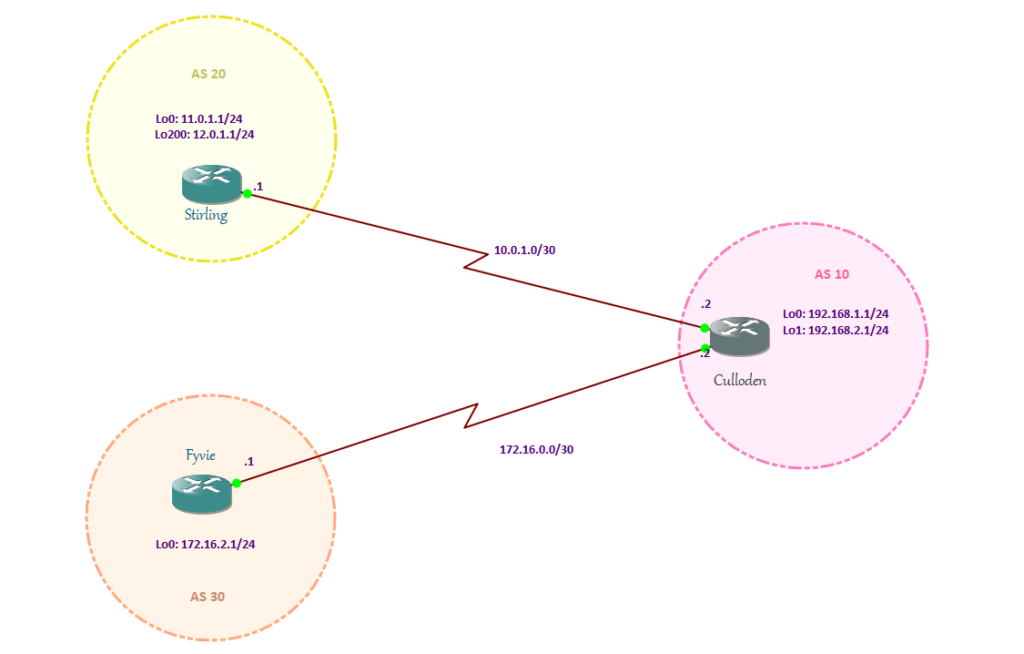
BGP Neighbor Adjacency States:
1. IDLE – This is normally can be seen if BGP is down / administratively down or just waiting for the next attempt. At this stage, no BGP incoming sessions are permitted.
My BGP is established between Culloden and Stirling sites and Culloden and Fyvie sites. But when I shut down s2/2 link between Culloden and Fyvie, my BGP went to IDLE state.
Culloden(config)#int s2/2 Culloden(config-if)#shut Culloden(config-if)#end
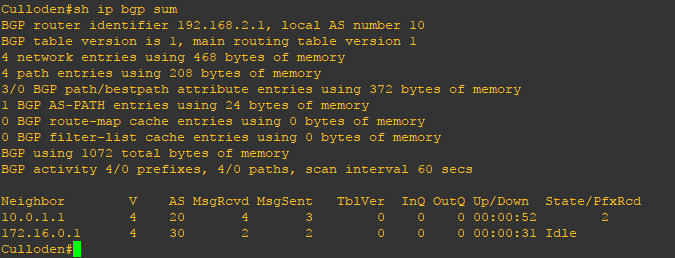
2. CONNECT – This is when BGP starts to do the TCP connection (TCP three-way handshake). Either of the BGP neighbors will initiate the BGP session. Once completed, it jumps towards the OPENSENT state. However, if there is a problem, it goes to ACTIVE state.
3. ACTIVE – At this stage, TCP connection is completed but no BGP messages have been sent to the BGP neighbor yet. There are many reasons why BGP is stuck in ACTIVE state. Usually, there are configuration issues that stop the BGP connection from getting established. It can be a wrong AS, misconfigured local IP / peer IP address, authentication issues, and others.

. OPENSENT – BGP Open message is already been sent to the peer but not yet received to the other end. You won’t usually see BGP stuck in OPENSENT state. It will immediately toggle to OPENCONFIRM state and ESTABLISHED states.
5. OPENCONFIRM – BGP Open message and keepalive has been sent and received. It won’t take long until it goes to the ESTABLISHED state.
6. ESTABLISHED – Once all the BGP requirements of establishing neighbor adjacency are met, it goes to the ESTABLISHED state. You will see prefixes Once adjacency is established between BGP neighbors, they are going to start exchanging routing information.
Putting back my s2/2 link up, makes my BGP back to ESTABLISHED state:
Culloden(config)#int s2/2 Culloden(config-if)#no shut Culloden(config-if)#end Culloden#
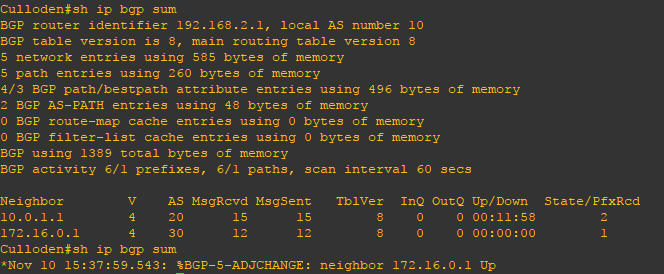
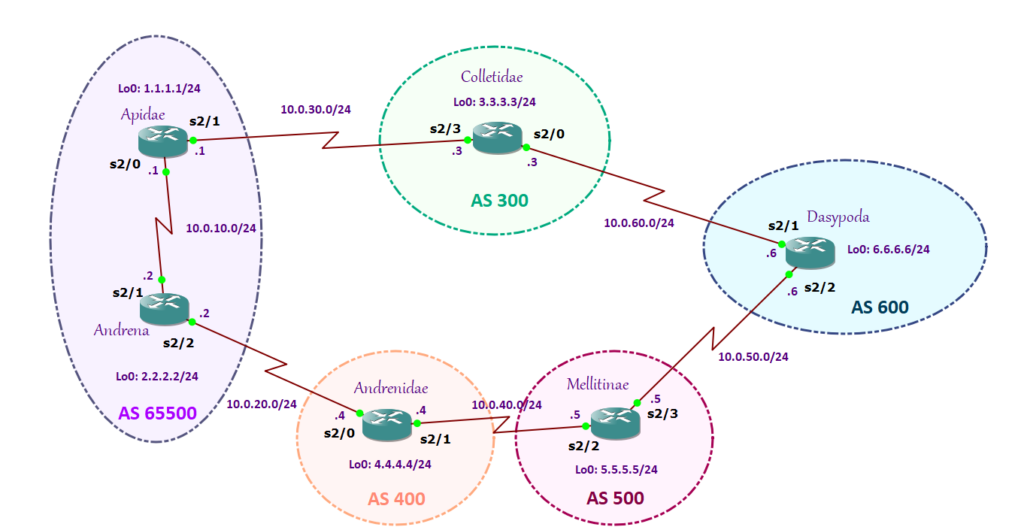
Let’s take this scenario.
Colletidae, a blellum lady living in the outskirt of Edinburgh, told her neighbor Apidae that Dasypoda is having an illegal affair with somebody else. Colletidae told Apidae that she can spread that in town. And, because Colletidae wants so much attention, she told her to tell everybody that she is the one who told her about it. Colletidae knows that everybody will believe Apidae as she is known to be an honest quine. Apidae cannot believe it and she told Andrena, sister of Andrenidae, about this.
“Don’t be such a wee clipe!”, said Andrena. “Are you the one spreading that rumor?”
“No, it’s not me. It’s Colletidae who told me about that.” Apidae replied.
When Andrena told her sister about this rumor,
“Who told you that?” Andrenidae asked
“Colletidae knows everything about Dasypoda’s affair,” Andrena whispered.
“Who is Colletidae?” Andrenidae asked.
Andrenidae, who is one of Dasypoda’s best friend, knows that it was her sister who told her about the affair rumor. What she didn’t know is that it was Apidae who told her sister about this and that Apidae knows where Colletidae lives.
This is true with partial mesh topology in iBGP. There is no route back to Colletidae.
With the use of next-hop-self command, it would force the iBGP speakers to advertise the route with the next hop address of its own.
Let’s do a simple lab about this scenario.
Let’s see what will happen after Dasypoda advertised its loopback address.
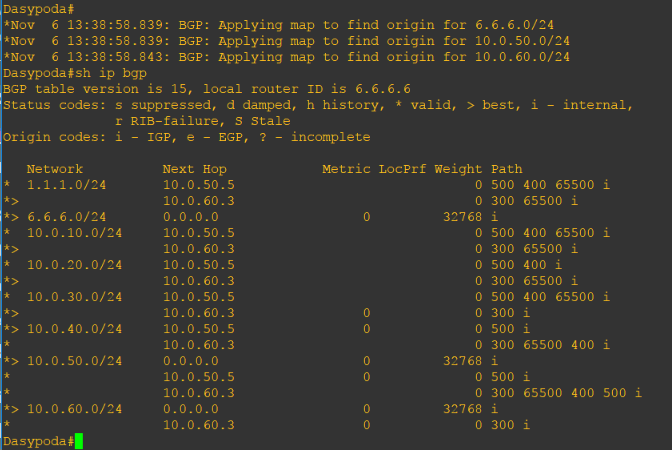
Enter configuration commands, one per line. End with CNTL/Z. Dasypoda(config)#router bgp 600 Dasypoda(config-router)#network 6.6.6.0 mask 255.255.255.0 Dasypoda(config-router)#end
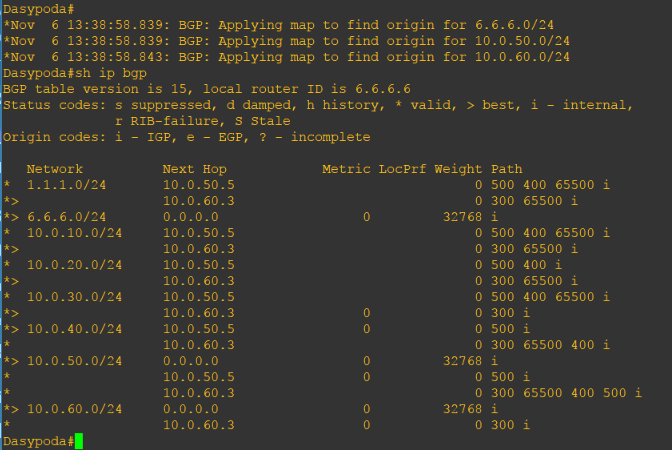
After Dasypoda advertised its loopback address, Colletidae learned it and install it in its routing table:
Local Preference is used to influence outbound traffic. The higher value is preferred over the lower one.
Let’s take an example.
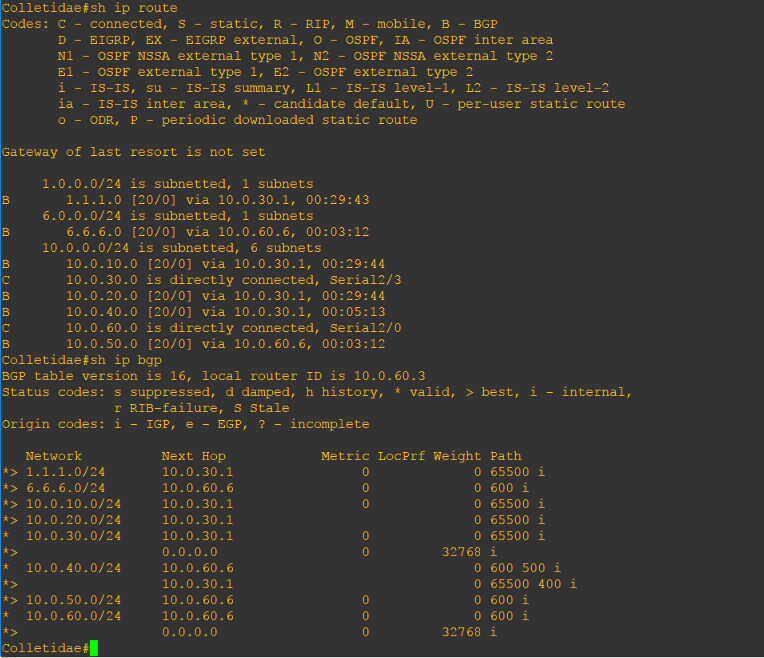
Looking at my diagram, to route traffic to Dasypoda, if we have all BGP attribute set as default, what path will Apidae take? Is it going to be Colletidae (10.0.30.3)->Dasypoda (10.0.60.6) or Andrenidae (10.0.70.4)-> Mellitinae (10.0.40.5) -> Dasypoda (10.0.50.6)? If we didn’t set the Local Preference, it will surely go to Collitidae (10.0.30.3)->Dasypoda (10.0.60.6) path.
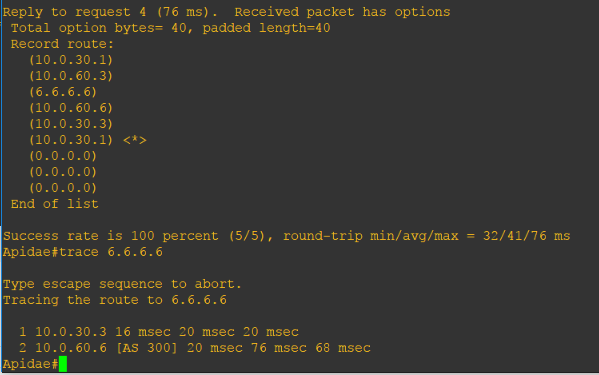
Let us check the routing table to know why it prefers the Colletidae (10.0.30.3)->Dasypoda (10.0.60.6) path:
As you can see, the valid best path to 6.6.6.0/24 is through 10.0.30.3.
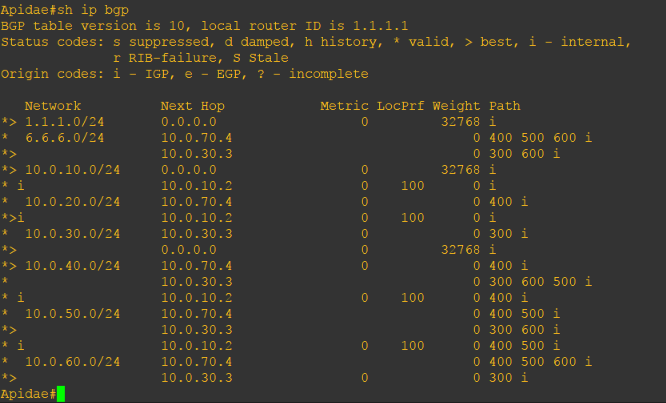
The question is why? Since Local Preference is not configured, BGP checks the next path selection attribute which is the AS Path. The shortest is more preferred. However, we do not want the Colletidae (10.0.30.3)->Dasypoda (10.0.60.6) path. We want the packet to take the Andrenidae (10.0.70.4)-> Mellitinae (10.0.40.5) -> Dasypoda (10.0.50.6) path. So how are we going to do it? Let us configure the Local Preference.
Apidae(config)#route-map PRIMARY-PATH permit 10 Apidae(config-route-map)#set local Apidae(config-route-map)#set local-preference ? <0-4294967295> Preference value Apidae(config-route-map)#set local-preference 250 Apidae(config-route-map)#exit Apidae(config)#router bgp 65500 Apidae(config-router)#neigh 10.0.70.4 route-map PRIMARY-PATH ? in Apply map to incoming routes out Apply map to outbound routes Apidae(config-router)#neigh 10.0.70.4 route-map PRIMARY-PATH in Apidae(config-router)#end
Now that the LOCAL PREFERENCE is changed to prefer the route to neighbor Andrenidae, the path Andrenidae (10.0.70.4)-> Mellitinae (10.0.40.5) -> Dasypoda (10.0.50.6) is now considered as the best valid path in the BGP table.
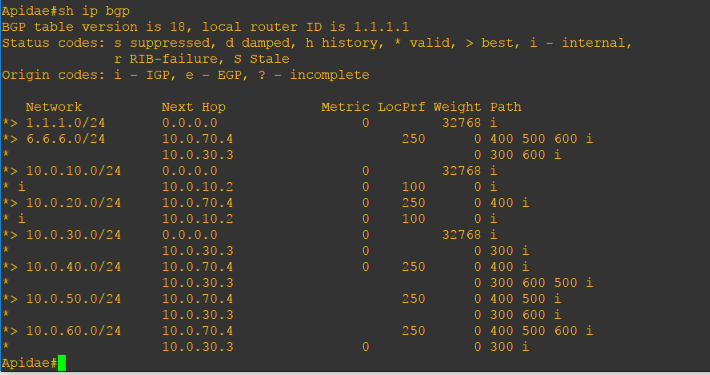
There is another way of manipulating the Local Preference and it is through bgp default local-preference command. Keep in mind that it is just changing the default value of Local Preference from 100 to the value you entered.
Before we end this discussion, what can you notice about this ping result?
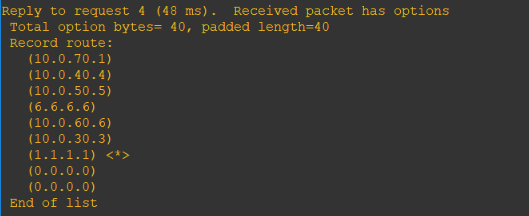
We have configured the Local Preference and it works as it prefers the Andrenidae (10.0.70.4)-> Mellitinae (10.0.40.5) -> Dasypoda (10.0.50.6). But what happened to the return traffic? We will see why on our next topic – BGP Multi-Exit Discriminator (MED).
]]>BGP has many attributes in choosing the best path. It is like an ice cream. It has many flavors. I bought Gianduia flavor from Gelato Messina while I was preparing this topic. I think I need loads of sugar to feed my brain as this BGP topic is robust and every attribute can be well-explained if we are going to lab it.
BGP’s attributes are mainly for path manipulation and these can influence either outbound or inbound traffic. It has a systematic process that it uses to choose the best path in the network.
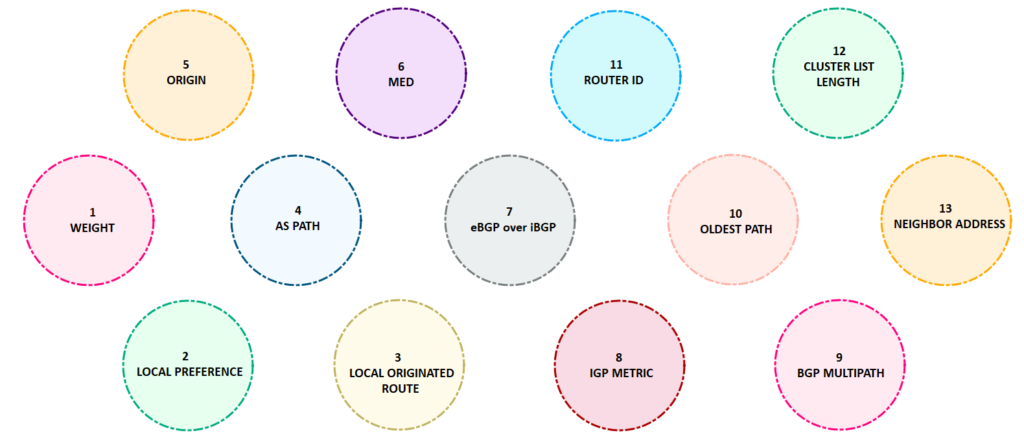
The first thing that BGP checks is whether the WEIGHT is configured or not. WEIGHT is Cisco Proprietary so it is obvious that it prioritizes Cisco devices which has BGP WEIGHT configured. In short, if you are using Cisco devices, WEIGHT is the first thing it checks before it goes on with the series of standard BGP attributes. Keep in mind that WEIGHT is local to the router and doesn’t pass to other routers. The higher the value is more preferred.
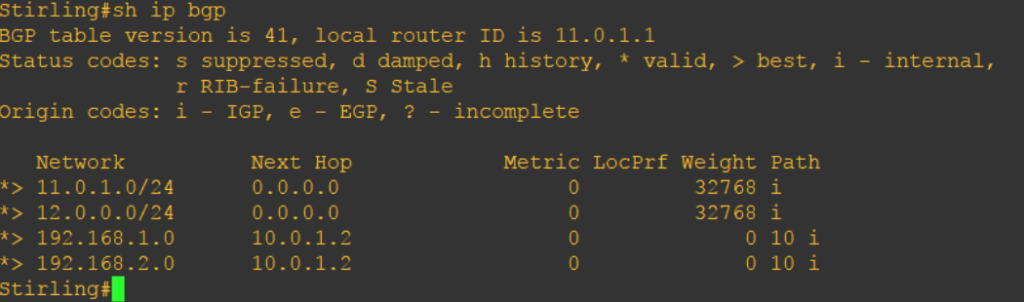
Next in line is the LOCAL PREFERENCE. This attribute influences the outbound routing. The higher value is preferred. Unlike WEIGHT, which has a default value of 0, LOCAL PREFERENCE has a default value of 100.
If LOCAL PREFERENCE is not configured, BGP looks for locally originated routes. As the name suggests, it is a route originated by the local router via network statement, redistribution, or aggregate statement. If you do “show ip bgp” routes with weight set to “32768” is considered as local routes. When weight is configured check for routes with next hop of “0.0.0.0.” You can also use “route-map localonly” command to get locally originated routes. It is also local to the router an not pass to other peers.
The most commonly used BGP attribute is the AS PATH. Unlike, LOCAL PREFERENCE, AS Path is a Well-Known Mandatory attribute and this attribute influences inbound routing. It should be present in every update and should be recognized by all BGP speakers. When a router running BGP session sends an update to its peer, it appends its own AS number. The shorter the AS path length is more preferred. To manipulate the incoming traffic to our preferred route, we can use the “as-path prepend” command.
Like, AS PATH, ORIGIN is also a Well-Known Mandatory attribute. In this attribute, the lowest is preferred route. IGP is lower than Exterior Gateway Protocol (EGP), and EGP is lower than INCOMPLETE. If you do “show ip bgp” you will see ORIGIN codes at the far right portion: i – IGP, e – EGP, and ? – incomplete. You will no longer see “e” in the “show ip bgp” output as it is already obsolete. The question mark “?” indicates redistribution and “i” means the network command is used to advertise the route.
Multi-exit Discriminator (MED) is an optional non-transitive BGP attribute. It is usually not used as the first five attributes are often utilized before this one. MED can influence routers in the same AS (iBGP) but not on different AS (eBGP). When a router learns a route from a peer, the MED’s value is kept and retain to its iBGP peers, but the value will be peeled off once it passed to eBGP peers. You can use the “set metric” command under the BGP router process if you are using a route-map or use the “default-metric” command. Take note that the lowest MED value is preferred over the higher MED value.
If MED is not configured, it checks whether the route is learned via iBGP or eBGP. Routes learned via eBGP is more preferred than routes learned via iBGP. If both routes are learned via eBGP then it chooses the lowest IGP value (administrative distance) to the next hop.
BGP Multipath is not considered as a tie-breaker but a determination if it can allow multiple installation of path in the routing table. The WEIGHT, LOCAL PREFERENCE, AS PATH, ORIGIN, MED value, same neighbor type (eBGP / iBGP) and IGP metric should match with the best path for it to be considered as an additional path to the destination. Be aware that if multipath is not enabled the default value is 1 which means it goes back to the BGP’s golden rule that it only chooses one best path to the destination.
The next step that BGP considers is the oldest route received. The oldest route in the routing table is preferred over the new ones. This step can be skipped if router ID is used for tie breaker and that the “bgp bestpath compare-routerid” command is used. If the command is used, the lowest router ID will be selected as the best path. If there is no manually configured router ID, the highest loopback IP is chosen and if still there is none, then the highest configured physical IP address. By the way, before you considered the highest physical IP address, it is necessary to check the route with minimum cluster list length configured. This is present in a route reflector environment. There’s more about this when we get to the route reflector topic.
Before we end this topic, let me remind you that before it goes to these 13 procedures, the first thing that BGP check is whether the next hop is reachable or not. What’s the use of all of these if the route is not reachable anyway?
- AS Path, BGP, BGP attributes, BGP multipath, BGP path selection, Border Gateway Protocol, eBGP, EGP, iBGP, IGP, Local Preference, MED, Multiexit Discriminator, Origin, route reflector, router ID, Weight
- 5 Comments
5 comments on “BGP Path Attributes: The BGP Path Selection Process”
- Pingback: BGP Path Attributes Types – Sassenach Learns
- Pingback: iBGP: BGP Next-Hop-Self Command – Sassenach Learns
- Pingback: BGP Local Preference Attribute: The Higher The Better – Sassenach Learns
- Pingback: The Internet Protocol: Border Gateway Protocol (BGP) Overview – Sassenach Learns
- Pingback: BGP Route Reflectors (RR) – The iBGP Reflection Mechanism – Sassenach Learns
Leave a Reply
Your email address will not be published. Required fields are marked *
Comment
Name *
Email *
Website Search